ELM-FATES Cross-Gridcell Seed Dispersal Design
Introduction
The goal of this software update is to take a fraction of the seed recruitment pool within a given fates site and pass further fractions of that seed amount to other fates sites located on neighboring grid cells.
Design Considerations
A gridcell-to-gridcell distance calculation function will need to be included that accounts for the curvature of the earth.
Assumptions and Dependencies
Given that the fates code should be designed with support for both CLM and ELM in mind, the design of the fates interface should be conducted such that it requires as little hlm-specific variation as possible to reduce duplication of effort.
The current allocation of fates sites to gridcells is 1:1 and as such it is assumed all seeds coming into a gridcell are completely allocated to that site. This may change in the future.
The location of the fates site within a given gridcell is not defined relative to the gridcell location. As such it is assumed to be located at the gridcell lat/lon.
The current assignment of the gridcell indices is via a simple round robin distribution method. This may change in the future.
Land decomposition and grid cell index assignment for both ELM and CLM is currently conducted in a similar manner. This may change in the future.
There is an assumption to be made about the maximum extent to which a given set of gridcell neighbors includes. Mathematically, extremely small fractions of seeds could be dispersed to all other gridcells on the globe, but realistically, some limit should be included. This also is assumed to make the neighborhood determination more tractable.
The design should not assume a cartesian grid layout (i.e. it should support unstructured grids).
It is assumed that the process indexing assignment is not dynamic (i.e. it is fixed at initialization and across restarts).
General Constraints
The design will initially be implemented in elm-fates. This communication routine should not conflict with future gridcell communication efforts. As such all design is recommended to be exclusive to fates as much as possible.
Given that the seed dispersal will need to communication with processes that will likely not be on the same node (due to round robin process assignment), the design should conduct the nearest neighbor determination as infrequently as possible. Additionally, the design should minimize the amount of process IO as possible.
Solutions
Gridcell communication options
Global gridcell knowledge: Continue use of simple MPI all routine to provide all processes global knowledge of every possible gridcell neighbor
Pro: relatively simple to implement, undestand and maintain.
Con: relatively inefficient in both communication and memory compared to other options.
Halo-implementation: Create “ghost” cells associated with the processes that need to communicate across nodes
Pro: More memory efficient and reduces overall amount of message passing.
Con: More complicated to impliment resulting in more maintenance as it requires custom infrastructure. Not ideally suited to round robin distributions?
MPI distributed graph routines
Pro: MPI native routines will have more long term support and requires less infrastructure setup. Potentially more efficient than Halo-implementation.
Con: Requires MPI 3.0 at a minimum; not all host land models may be compatible with MPI 3.0 explicilty.
ESMF graph routines
Pro: Same as MPI distributed graph routines in the level of support and reducing infrastructure maintenance costs. Utilized by CLM.
Con: Not compatibe with all host land models. ESMF support is not expected to be available for ELM.
Currently this design utilizes the simpler global gridcell knowledge option as it was determined that developing a scientifically useful module took precence over computational performance at this stage. Future improvements geared towards performance are currently favoring the MPI distributed graph routines as these provide a common denominator to both host land models.
Design and Architecture
The design of the grid cell to grid cell seed dispersal structure is generally comprised of three new parts:
Nearest neighbor determination
Dispersal kernel implementation
Gridcell-to-gridcell communication across nodes (i.e. dispersal)
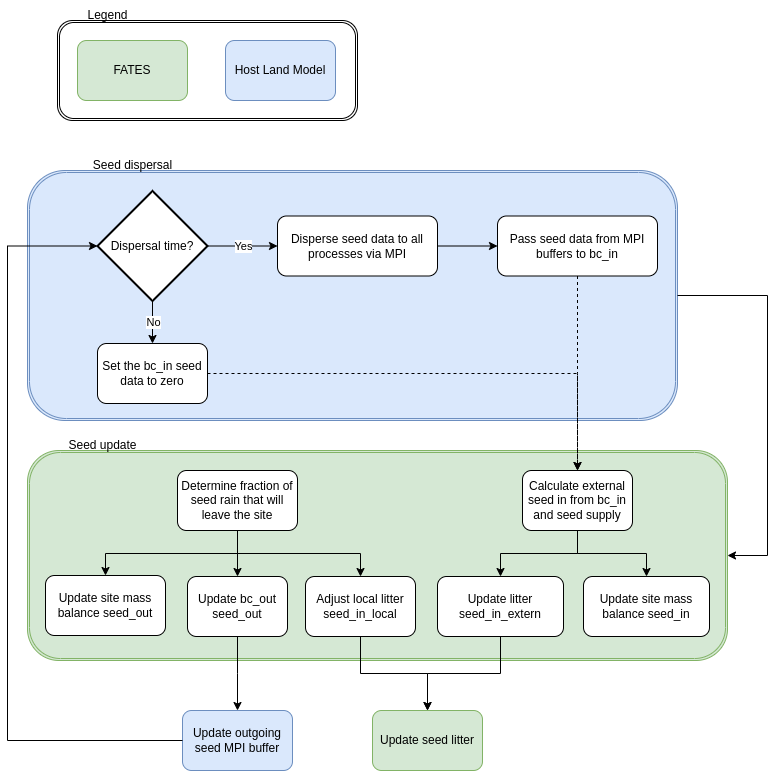
The nearest neighbor determination occurs during initialization based on 8. in the above assumptions. The pseudocode for the algorithm is presented below. A maximum neighborhood distance is specified to avoid distributing extermely small, unrealistic values. The disperal kernel is called during the neighbor determination to calculate a probability density based on the pft-specific parameters which is stored in a neighbor object associated with a given gridcell. This pre-determined probability density is utilized during the dispersal process within a given timestep update, but itself stays constant over time. The overall seed dispersal and associated update process is portrayed in the flowchart below.
System diagram or flowchart
The following flowchart depicts the general process of the seed dispersal code:
Algorithm or Pseudo code for main components
The following pseudo code describes how the nearest neighbor data structure is formulated. The algorithm looks ahead through the list of gridcell indices for a gridcell that is close to it. When it finds one, it calculates the probability density and stores it in a neighborhood linked list associated with that gridcell. It then copies that information into the gridcell that was found to reduce duplication of calculations:
\begin{algorithm}
\caption{Determine Gridcell Neighbors}
\begin{algorithmic}
\REQUIRE globally-available array of gridcell indices: $gdc2glo$
\REQUIRE globally-available domain decomposition information with lat/lon for all gridcells
\OUTPUT array of linked lists: $neighbors$
\PROCEDURE{DetermineGridCellNeighbors}{$neighbors$}
\STATE $G = $ \CALL{size}{$gdc2glo$}
\STATE Initialize $neighbors[G]$
\STATE Initialize $lat[G]$ and $lon[G]$ arrays
\STATE Pass lat/lon domain information out to all processors into $lat[G]$ and $lon[G]$
\FOR{$i = 1$ \TO $G - 1$}
\FOR{$j = i + 1$ \TO $G$}
\STATE $gd = $ \CALL{GreatCircleDistance}{$i,j,lat,lon$}
\IF{\CALL{any}{$gd < maxdist[ipft]$}}
\FOR{$ipft = 1$ \TO $numpft$}
\STATE Create $Ineighbor$ object
\STATE $Ineighbor.index = gdc2glo[j]$
\STATE $Ineighbor.pdf = $ \CALL{ProbabilityDensity}{$gd,ipft$}
\STATE Append $Ineighbor$ to $neighbors[i]$
\STATE Create $Jneighbor$ object
\STATE $Jneighbor.index = gdc2glo[i]$
\STATE $Jneighbor.pdf = Ineighbor.pdf$
\STATE Append $Jneighbor$ to $neighbors[j]$
\ENDFOR
\ENDIF
\ENDFOR
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
Rollout Plan
Refactor and update original code base along with parameter file. Conduct simple build and test run cases.
Scientific testing and validation on local repositories. Update code and parameter file as necessary.
Generate couple e3sm and fates pull requests and conduct final review and regression tests.
Future Update Plan
Reduced processor communication overhead through improved nearest neighbor algorithm using host land model agnostic routines (i.e. not ESMF dependent).
Appendix
Bullock, et al (2017). A synthesis of empirical plant dispersal kernels. https://doi.org/10.1111/1365-2745.12666